Синтез речи
Синтез речи – задача, решенная намного лучше, чем задача распознавания. Существует много методов синтеза речи, но в основе большинства из них лежит две модели: компилятивный синтез - синтез речи путем конкатенации (составления) записанных образцов отдельных звуков, произнесенных диктором, и формантно-голосовая модель, в которой моделируется с той или иной степенью точности речевой тракт человека. Первая модель требует очень кропотливой работы по созданию звуковой базы данных, и самообучение этой модели представляется крайне затруднительным. Вторая модель, напротив, допускает самообучение в широких пределах, хорошо интегрируется в нейросетевую модель, но в связи со сложностью моделирования речевого тракта человека обладает низкой точностью синтезируемого звука. Тем не менее, уже при довольно простом моделировании синтезируемые звуки разборчивы, поэтому для исследовательских целей она предпочтительней первой.
Для построения модели синтеза речи естественно разобраться, каким образом речь синтезируется человеком. На рис. 3 схематически изображен речевой аппарат человека (см. [5]).
Речевой аппарат человека
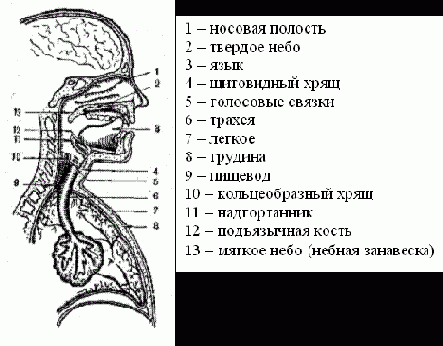
Рис. 3
Дыхательные органы (легкие, бронхи, дыхательное горло) служат для передачи звуковых колебаний, возникающих в артикуляционном аппарате, во внешнюю среду. Источником колебаний при образовании звуков речи могут быть прежде всего голосовые связки. Голосовой источник принимает активное участие в образовании гласных и всех звонких согласных: колебания голосовых связок образуют основной тон голоса, частота которого зависит от физических свойств связок (в основном от длины и толщины) и степени их натяжения (что дает возможность изменять основной тон в широких пределах). Кроме основного тона голосовой звук содержит большое число гармоник. В основном это гармоники, кратные основному тону, и их появление хорошо объясняется теорией колебаний.
Кроме голоса, возможны другие источники звука, а именно – шумовые источники – турбулентный и импульсный. Турбулентный шум образуется при наличии сужения в каком-либо месте речевого аппарата.
В результате этого воздушный поток, поступающий из легких по относительно широкому проходу, в месте сужения создает вихревые потоки, вызывающие специфический шум, который мы слышим при образовании таких согласных, как с, ш, х. Импульсный источник вызывает звук при образовании таких согласных, как п, т, к, когда происходит резкое прерывание воздушной струи, создается избыточное давление за местом смыкания артикуляционных органов, а затем его внезапный спад при раскрытии смыкания.
Но кроме действия этих трех источников и их комбинаций вклад в звукообразование вносят резонансы
в многочисленных полостях речевого тракта. Резонансы могут усиливать или ослаблять какие-то частоты, тем самым ещё больше усложняя звук. Эти усиленные частоты называются формантами. Число формант ограничено, специалистами выделяется не более четырех формант, активно участвующих в речеобразовании ([5]). В процессе речеобразования происходит постоянное изменение формант в результате изменение положения артикуляционных органов, их твердости, объема полостей, и т.д. На рисунке 4 четко виден формантный состав гласных и и у. При переходе от гласной и происходит смещение частоты форманты F2 c 2400 Гц на 784 Гц и одновременное ослабление формант F3, F4. (Спектр получен инструментом Анализатор для файла а-о-и-у.wav при размере окна FFT 256 сэмплов, окне сглаживания Хэмминга и логарифмическом масштабе).
Спектр файла “а-о-и-у.wav” при переходе с и
на у.
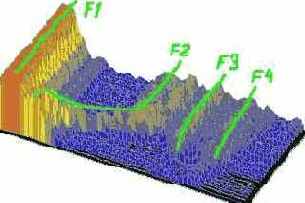
Рис. 4
Образование шипящих звуков также хорошо объясняется действием резонансов. Например, спектр звука х представляет собой шум с характерной для резонансов огибающей (рис. 5)
Спектр файла х.wav

Рис. 5
Построение формантно-голосовой модели синтеза речи подробно описывается в разделе 5.3.
