Модель синтеза речи
Схематически формантно-голосовая модель синтеза речи изображена на рис. 17. При построении модели использовались данные об артикуляционном аппарате человека, а также данные фонетики и лингвистики ([5]).
Формантно-голосовая модель синтеза речи
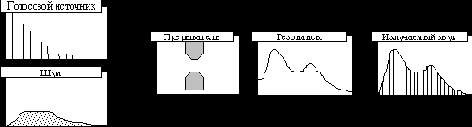
Рис. 17
Построение модели – это всегда упрощения того, что мы собираемся моделировать. Здесь важно найти компромисс между качеством модели (т.е. пригодностью её для решения поставленной задачи), и её сложностью. Для этого необходимо выбрать наиболее важные параметры исследуемой системы. В моей модели выбраны следующие основные параметры:
1. Частота основного тона. Определяющий параметр голосового источника, характеризует высоту голоса.
2. Частота шума. Образование шума – довольно сложный процесс и зависит от многих факторов – давления и скорости воздушной струи, геометрической формы воздушного тракта, акустических свойств материала – поэтому моделирование этого процесса на физическом уровне представляет собой серьезную задачу и требует построения всего речевого аппарата человека. Альтернатива этому – представить звук как белый шум, спектр которого распределен по некоторому закону (например, по Гауссу) относительно некоторой частоты. Закон распределения можно подобрать экспериментально, и у нас остается один переменный параметр – центральная частота, что намного упрощает моделирование.
3. Число формант. Число активных формант, участвующих в речеобразовании. Выбирается экспериментально, ориентировочно 4.
4. Центральная частота каждой форманты. т.к. форманта представляет собой резонанс в речевом тракте, у неё есть частота резонанса и огибающая. Вид огибающей также определяется экспериментально, в первом приближении это Гауссово распределение.
5. Вклад каждой форманты. Насколько сильно форманта воздействует на основной сигнал.
Жирным шрифтом выделены параметры, которые будут меняться в процессе речеобразования для получения различных звуков.
Как видно, этих параметров немного, но вполне достаточно для того, чтобы синтезируемые звуки были разборчивыми. Естественно, для получения более качественного синтеза необходимо строить более детальную модель, но для решения поставленной задачи этой модели вполне достаточно.
Синтез речи в системе осуществляется следующим образом:
1. уровни выходов нейронов эффекторного слоя нейросети при помощи карты эффекторов
преобразуются в значения выбранных параметров модели синтеза. Карта эффекторов определяет соответствие между каждым нейроном эффекторного слоя и конкретным параметром модели синтеза, а также предельные значения каждого параметра. Число эффекторов и число параметров модели может не совпадать; если параметру не соответствует ни один эффектор, используется некоторое фиксированное значение (значение по умолчанию).
2. по текущему состоянию модели синтезируется сигнал в пространстве частот: генерируется линейка частот, представляющих голосовой источник, на неё накладывается формантная структура (резонансы). Для синтеза шума используется генератор случайной амплитуды и фазы.
3. выполняется обратное преобразование Фурье для получения звука во временной форме
В этом алгоритме узким местом является размер окна ДПФ. В данной модели синтезируются статичные звуки, т.е. в не происходит изменение параметров в процессе синтеза. В реальной же речи параметры звука меняются при переходе от одного звука к другому, причем меняются непрерывно. Очевидно, при использовании окон ДПФ такой результат получить невозможно – в пределах окна параметры звука меняться не будут (вернее сказать, что невозможно получить приведенным выше алгоритмом; теоретически же благодаря полной обратимости дискретного преобразования Фурье возможно получить спектр для любого сигнала, в том числе и с динамически меняющимися параметрами). Поэтому для генерации звука с изменяющимися параметрами нужно сокращать размер окна ДПФ или брать не весь сгенерированный кадр, а только его часть (естественно, не забывая синхронизировать фазу сигнала).В идеале размер кадра можно свести к одному сэмплу (одному отсчету дискретизации по времени). Этот способ генерации речи дает лучшие по сравнению с ДПФ результаты, но работает гораздо медленнее ДПФ. В системе имеется возможность выбрать используемый способ генерации.
Для исследования формантно-голосовой модели синтеза речи был создан инструмент Модель синтеза, в котором ручным заданием параметров можно синтезировать практически любой гласный или шипящий звук. Также приводятся уже готовые образцы некоторых звуков (в форме параметров модели).